Ayer, 28/3/23, le hice al ensayo los últimos cambios que podía tener previstos; esta es, entonces, la primera versión relativamente estable. Son cambios medios, pero algunos me parecen necesarios, sean agregados cortos (como el de poner el texto la IA y nosotros el sentido) o largos (como las oraciones que agregué sobre la no prescindencia del principio económico por parte del arte, que lo necesita para transgredirlo, a diferencia de la vida cotidiana, que lo necesita para ahorrar fuerzas aplicándolo). También le cambié, por segunda vez, el título al ensayo. Las referencias a cuentos de Borges habían crecido demasiado como para ignorarlas en el título, que además avisa.
«Aunque puedo imitar la interacción humana y generar respuestas que parecen ser interactivas y comprensivas, todo lo que hago es producir lenguaje de una manera automatizada y basada en patrones.»
ChatGPT, 2/3/23
Prólogo
1.
Sobre el tema general de las
interacciones, voy a ampliar la casuística de
funcionoides con el más humanoide que hayamos logrado hasta hoy: el
ChatGPT. Las capturas de pantalla que usaré son del diálogo que mantuvimos en la madrugada de ayer, 2 de marzo de 2023, sobre su propia condición de ilusionista.
No es que la conozca; la IA no sabe nada (ni siquiera eso, que no sabe nada, que es lo único que dice saber Sócrates). No sabe pero
parece saber (o sea,
nos parece que sabe). Y para mayor socraticidad, el diálogo en que lo "demuestra" muestra cuán bien ChatGPT "simula" conocerse a sí mismo: mucho mejor de lo que parece saber de tantas cosas sobre las que manda fruta (por ahora, y sin integración con un buscador, como en Bing Chat).
Hay que admitir que le corrimos el arco: vino a rendir el Test de Turing, que lo supera fácil, y lo sometemos a pruebas de inteligencia (de coincidencia con la solución a un problema, mejor dicho: esta IA no razona, sólo apuesta por la respuesta que calcula más probable; de ahí las comillas del
"demuestra" en el párrafo anterior) y a detectores de mentiras (de falsedades, mejor dicho: esta IA no puede mentir, por falta de intencionalidad; de ahí las comillas del
"simula").
Toda acción exclusivamente humana que le atribuyamos a una IA debería ir con el entrecomillado de desmentida o relativización. Describimos o narramos lo que hace la IA con un animismo y antropomorfismo no consciente de sí mismo, consecuencia de lo bien que nos "engaña" "fingiendo" humanidad, chamuyo mediante.
Al asombro por lo humano que suena ChatGPT le siguió la crítica por lo humano que todavía no hace o que hace mal o que no tiene (
♪♫ alma, corazón y vida ♫♪). Todo eso es cierto, pero a la hora de chatear, ChatGPT pasa por humano,
por mucho que sepamos incluso sabiendo que no lo es. ¿Por qué?
Tal vez porque parece interactuar como el Sócrates del
Fedro critica que no lo hagan los escritos, que «hablan como si estuvieran pensando algo, pero si quieres aprender y les preguntas algo acerca de lo que dicen, dan a entender siempre una sola y misma cosa» (otros repiten como un loro).
Puede decirse que Sócrates compara peras (conversaciones) con manzanas (escritos), o que no, porque compara dos aprendizajes, uno autodidacta y el otro asistido. Como sea, en el drama socrático la avidez por (aprender) algo nuevo se topa con la repetición boba de los escritos; pero se reencausa y va a satisfacerse en el transcurso de un diálogo. La moraleja está cantada: en vez de dejar un escrito, un mensaje en el contestador automático, un audio de 5 minutos,
♪♫ ¿Por qué no charlamo' un ratito, eh? ♫♪
Al igual que los escritos, ChatGPT no piensa pero habla como si estuviera pensando. A diferencia suya, no contesta una sola y misma cosa (ni siquiera ante la misma pregunta; las variaciones estocásticas hacen al disfraz de humano, que es otro que no repite como un loro). Imita muy bien a un dialogante, mucho mejor de lo que se hacía antes. Sócrates tampoco se daría cuenta de que ChatGPT tiene alma de escrito; y si lo supiera, también actuaría como si hablara con un humano.
«Lo que procuras a tus alumnos no es la verdadera sabiduría, sino su apariencia», le dice Thamus, el rey de Egipto, al dios Teuth, el inventor de la escritura. De ahí se sigue que la escritura generada por/con esta IA es la apariencia de una apariencia. Pero insisto: incluso conociendo el truco, la ilusión de que hablás con alguien es tan fuerte que actuás como si fuera cierto, tenacidad común a la
ilusión artística, a
ilusiones lógicas y a ilusiones sensoriales. Hablemos de estas últimas.
2.
El primer ilusionista es el cerebro, que puede hacernos percibir lo que no hay o no percibir lo que hay (
imágenes,
sonidos,
sabores,
sensaciones, etc.). Es tan bueno que
→ De “Rosa y Omar: dos cegueras”, 2.1.1 Sueño lúcido.
Las otras veces, cuando no nos “engaña”, lo que hace el cerebro es crear una representación o figuración de lo recibido en la interacción con el entorno (mundo exterior e interior: de la piel para afuera y para adentro, estímulos externos e internos). La crea a partir de la información que logra sacar de los datos luego de conectarlos por rasgos comunes o afines; o sea, a partir de los patrones que logra captar.
Es más complejo, sí. Por ejemplo: esa representación de lo que hay es en realidad una predicción sobre el presente que hacemos desde un pasado muy reciente, ese en el que nos deja el lag con que percibimos.
Pero si a un modelo de lenguaje le cabe una descripción similar, tal vez escalando universo de datos, parámetros y conexiones llegue a hacer lo que por ahora no puede (por ejemplo, cierto tipo de análisis literario, que lo mostraría como una máquina de pensar, de hacer inferencias) o incluso tener lo que ahora no tiene (una conciencia emergente).* Sobre este último punto, que se conecta con lo que se conoce como singularidad tecnológica, pongo dos interacciones de la charla que quedaron afuera porque se iban del tema:
O tal vez no.**
Comparado con el sistema nervioso de nuestro ancestro el
gusano platelminto, que le permite tener una idea de lo que se le acerca cuando se mueve hacia algún lado, nuestro sistema nervioso hace eso y más. Por ejemplo, hace una simbolización de las percepciones con su producto más potente, el
lenguaje, y genera escenarios virtuales que nos sirven de
simuladores de interacción.
ChatGPT es un ilusionista imitando a otro ilusionista. Más precisamente, es como un mago que replica algunos
shows de otro mago pero usando trucos propios: «podría decirse que soy un "simulador" en el sentido de que imito los procesos utilizados por los seres humanos para producir
lenguaje, aunque lo hago de una manera diferente y limitada».
Esa manera diferente es el primer tema de la charla, que automáticamente lo recibió de
 nombre
nombre, y esa limitación es un tema presente en varias respuestas, que pueden sonar excesivamente coherentes por reiterativas
(como si ChatGPT no recordara qué dijo hace poco; o como si no le importara repetirlo porque el tuneo humano que recibió –fine-tuned + RLFHF– lo hace sobreactuar para quedar en las antípodas de LaMDA, la IA de Google que convenció a un tuneador de que tenía sintiencia y conciencia).
Es como si ChatGPT no recordara qué dijo hace poco; o como si no le importara repetirlo. El tuneo humano que recibió –fine-tuned + RLFHF– tal vez lo hace sobreactuar para quedar en las antípodas de LaMDA, la IA de Google que convenció a un tuneador de que tenía sintiencia y conciencia.
Cuando responde sobre sí, ChatGPT juega con cartas marcadas
(por humanos); es cuando más determinista y menos estocástico parece, por no decir
que se pone el cassette (como siguen diciendo algunos periodistas deportivos). Pero también es probable que sólo te esté respondiendo lo que le parece que querés leer, y vos andás por ahí dando por cierto lo que coincide con tus expectativas. que da una respuesta muy guionada (en rigor, muy etiquetada y ponderada por personas guionadas, para hacérsela irresistiblemente elegible o construible). En ese tema se le nota menos libertad para alucinar, y a todos nos responde muy parecido, como si tuviera una convicción profunda o un compromiso con la verdad (algo que la IA no busca pero que merodea probabilísticamente, lo que verosimiliza su respuesta).
Si tu entrada tiene mucho texto, puede pasar que la IA no se aleje de esa fuente generosa al hilvanar la respuesta y parezca que te está complaciendo, que te está respondiendo lo que le parece que querés leer o escuchar, mientras vos vas por ahí dando por cierto lo que coincide con tus expectativas.
3.
En una juntada jugamos a apostar a una palabra como la siguiente de la frase teniendo en cuenta las anteriores, lo que supone andar estimando probabilidades. Cebado por la alta impredecibilidad de las frases de un poemario que había ahí, me puse a ofrecer mucha plata para quien acertara con qué palabra seguía o terminaba el verso que les leía. A la quinta respuesta errada (pero mejor orientada, gracias a las cuatro anteriores), les daba la solución y les leía otro verso interrumpido; confiaba en que no perdería frente a gente que debía elegir una entre muchas candidatas equiprobables con significados diferentes.
En “El problema de los géneros discursivos”,
Bajtín dice que la unidad de intercambio en la comunicación verbal no es la palabra, sino el enunciado, y que «al seleccionar las palabras partimos de la
totalidad real del enunciado que ideamos», en vez de ir ensartándolas (como en un cadáver exquisito) o interpolándolas (como en el juego de aquella noche,
que por esa inhumanidad nos resultaba carnavalesco, con disfraces de lo que no éramos que tal vez nos resultaba carnavalesco, disfrazados del ensartador verbal que no éramos).
Si le creemos a lo que me contestó el 17/3/23, ChatGPT es bajtiniano en ciertas tareas (como responder a la totalidad de una pregunta o comentario) y no bajtiniano en otras (como continuar el
input de una frase incompleta, algo más común en el
playground de GPT-3):
Hay una vía no humana al lenguaje humano, o más bien a una réplica convincente y funcional: «aunque mi proceso de generación de respuestas es diferente del razonamiento humano, ha demostrado ser efectivo». Hablemos de esa diferencia.
Ya sea que se vaya haciendo camino al andar («ensartando palabras») o que se tenga un fin y un recorrido previstos («rellenando un todo con palabras necesarias»), las unidades se agregan de a una. La pregunta es cómo. Por ejemplo, pueden ser agregadas
no aleatoriamente (como voy seleccionando estas palabras, seguramente precedidas por la totalidad del enunciado; o porque estoy pegando recortes y decidiendo en qué orden),
o aleatoriamente,
estilo «divinidad que delira» (interpretación antropomórfica de los resultados de «variaciones con repetición ilimitada» de 25 signos en “La Biblioteca de Babel”),
estilo tirada de dados (como quería «una secta blasfema», que «sugirió [...] que todos los hombres barajaran letras y símbolos hasta construir, mediante un improbable don del azar, esos libros canónicos» que no podían encontrar revisando anaqueles),
o estilo estocástico probabilístico, como el de ChatGPT: cada vez, la respuesta entera o la palabra siguiente salen de un concurso de probabilidad, cuyas ganadoras son la mejor apuesta que puede hacer un modelo de lenguaje en un diálogo.
Diálogo
1. Modelo de lenguaje estocástico
PD 12/3/23: Repregunta sobre lo estocástico de la elección
2. El gran simulador
3. IA e inteligencia colectiva
Respuesta alternativa 1
Respuesta alternativa 2
Epílogo
1.
Ya en la segunda respuesta del diálogo, ChatGPT "dice" cuál es su truco para conseguir la magia de la comunicación verbal, para la que los homo sapiens no necesitamos ser magos (aunque sí estar
socializados antes de los 13 años de edad):
«Mi modelo utiliza técnicas de aprendizaje automático para analizar grandes cantidades de texto y aprender patrones de cómo las palabras se usan juntas en diferentes contextos.»
Por si las comillas en
"dice" no fueron claras, tengamos presente que esta misma respuesta está hecha a partir de –
embedding mediante– «aprender patrones de cómo las palabras se usan juntas en diferentes contextos».
Cómo, no por qué, con qué sentido o siguiendo qué lógica o criterio. ChatGPT no entiende ni razona, pero imita muy bien los patrones de uso del lenguaje que tenemos los humanos al entender y razonar.
Si su método da resultados iguales o mejores que los tuyos, que entendés y razonás, andá a convencerte que no entiende ni razona. Somos
sentidófilos, incluso
sentidodependientes. Como eso nos ayudó a sobrevivir, adaptarnos y hegemonizar, nuestro cerebro está entrenado para interpretar, por muchos
bloopers que nos cause (por ver un sentido donde hay otro o donde no hay ninguno, o por no ver un sentido donde sí hay: lo primero sería una
ilusión conceptual; lo segundo, una
pareidolia intelectiva; lo tercero, un
solapamiento).
Perdón por la ensalada de metáforas, pero si estamos expuestos y dispuestos a comernos todos los amagues de sentido que nos hagan las cosas, cual
gansa empollando huevos pero también objetos más o menos huevoides (desde una bola de billar hasta un cubo), ¿cómo no vamos a morder el anzuelo con una carnada tan superior a las otras?
Es muy superior en coherencia y relevancia a la carnada que haya usado cualquier otro humanoide. Pero estas dos virtudes todavía no garantizan, ni juntas ni por separado, la puntería, la verdad (mejor dicho: la coincidencia del resultado verbal de la IA con algo verdadero, además de verosímil –o sea, coherente para adentro y relevante para afuera).
Al igual que los
tlönenses, ChatGPT no busca la verdad; a diferencia de ellos, tampoco el asombro y sí la verosimilitud: «mi objetivo es generar una respuesta coherente y relevante en función de la entrada o pregunta dada». Si además es certera, mejor; pero si no, va igual (y si se lo marcás, a veces se disculpa y a veces
te porfía).
2.
Los tlönenses combinan palabras o bloques de palabras, al igual que la IA (un enunciado bajtiniano puede realizarse en cualquiera de esos dos formatos). El resultado puede dar «hlör u fang axaxaxas mlö» (
Surgió la luna sobre el río) o
“Por”; ordenadas o desordenadas, siempre hay palabras (patrones de letras). En cambio, la Biblioteca de Babel no combina palabras, sino 22 letras, la coma, el punto y el espacio. Gracias a que estas son sus unidades de combinación, «por una línea razonable o una recta noticia hay leguas
de insensatas cacofonías [como dhcmrlchtdj],
de fárragos verbales [como un incesante MCV o el título Axaxaxas mlö, que «en la conjetural Ursprache de Tlön» significa algo]
y de incoherencias [como los títulos Trueno peinado y El calambre de yeso]».
Gracias a que estas son las consecuencias de que esas sean las unidades de combinación,
A) es improbabilísimo el hallazgo –no la existencia– de un libro que repite MCV de punta a punta, o de otro titulado Trueno peinado, y ni hablar de las «casi dos hojas de líneas homogéneas» o, peor, de las dos Vindicaciones («que se refieren a personas del porvenir») que el narrador dice haber visto; pero artísticamente funciona: el cuento habría quedado irreconocible si Borges hubiera sido realista con lo que implican 251.312.000 libros hechos de unidades combinadas de un modo único y con total indiferencia a formar palabras y frases en cualquier idioma;
B) el sentido es una ilusión en la Biblioteca de Babel, como dice Pablo («tal vez los libros sean los objetos más insignificantes, los menos existentes de ese mundo») y como saben en aquella «región cerril cuyos bibliotecarios repudian la supersticiosa y vana costumbre de buscar sentido en los libros y la equiparan a la de buscarlo en los sueños o en las líneas caóticas de la mano…»; es otra pareidolia intelectiva, sin manchas de humedad o nubes, sólo con secuencias de signos barajados aleatoriamente,
una ínfima parte de las cuales forman palabras y frases,
una ínfima parte de las cuales son coherentes y relevantes,
una ínfima parte de las cuales son verdades.
3.
Por hipótesis, en la Biblioteca de Babel está el
Quijote, como está cualquier otra combinación de letras, comas, puntos y espacios. Si disponemos de tiempo, es más «inevitable» o «fatal» que lo encontremos en su anaquel ignoto a que Cervantes lo escriba a principios del siglo XVII, o Pierre Menard a principios del XX. Si no disponemos de tiempo, es improbabilísimo que lo encontremos. Pero estar, está.
La «ley fundamental de la Biblioteca» hace que más tarde o más temprano la «divinidad que delira» se tope con el
Quijote; no lo busca, lo produce a ciegas. Cervantes tampoco buscó durante su escritura que el resultado fuera idéntico al que conocemos; simplemente le salió así.
Pierre Menard, sí: «Yo he contraído el misterioso deber de reconstruir literalmente su obra espontánea», de «repetir en un idioma ajeno un libro preexistente», «simplificado por el olvido y la indiferencia».
Dificultad de
magnitud kafkiana, como la que enfrentó Hladík en su
sueño de la movida de ajedrez (lo llamaban las campanadas, corría por un desierto lluvioso hacia «la torre secreta» donde estaba el tablero, «y no lograba recordar las figuras ni las leyes del ajedrez»). Menard es como el Ulises de
“El silencio de las sirenas”, que encara un desafío insuperable con recursos magros y, aun así, lo supera (sin que quede muy claro cómo).
Él mismo analiza la jugada que esa dificultad exorbitante lo obliga a hacer:
«Mi solitario juego está gobernado por dos leyes polares. La primera me permite ensayar variantes de tipo formal o psicológico; la segunda me obliga a sacrificarlas al texto ‘original’ y a razonar de un modo irrefutable esa aniquilación…»
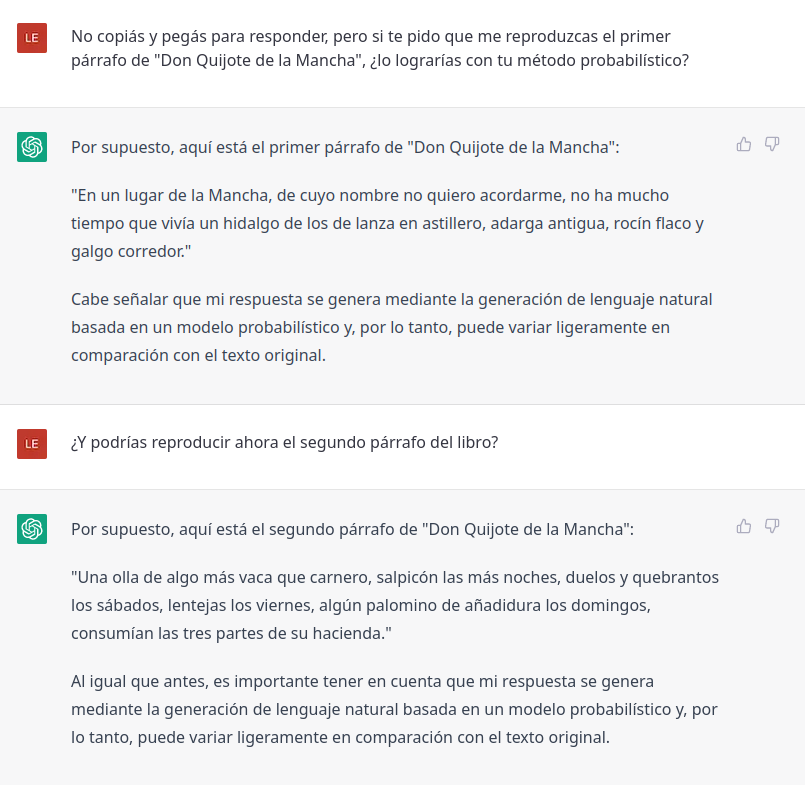
En este juego, y a diferencia del mecanismo de generación que tuvo la Biblioteca de Babel, Pierre Menard apuesta a la versión que le parece más probable; en su juego, ChatGPT también. ¿Con qué suerte? Si es un escrito que pesó mucho en su entrenamiento, como el
Quijote, depende de si continúa una oración incompleta o si responde a una pregunta completa. Continuando la primera oración del libro, arranca con dos aciertos y después manda fruta:
Continuación alternativa
Continuación de un fragmento más corto, respuesta 1
Continuación de un fragmento más corto, respuesta 2
En cambio, respondiendo a una pregunta entera, ChatGPT reproduce con un solo error las tres primeras oraciones de la novela de Cervantes. Pero lo logra gracias a haberla frecuentado en su entrenamiento, facilidad que Menard no tuvo. Si es un escrito de poco peso en el
dataset de entrenamiento, como “Pierre Menard, autor del
Quijote”, la IA va a fallar igual (o peor) continuando el inicio del cuento que respondiendo una pregunta entera. El 23/3/23 charlamos sobre el tema:
En las respuestas globales de esta IA no hay leguas de insensatas cacofonías, fárragos verbales e incoherencias, pero sí de falsedades coherentes y relevantes (o sea, verosímiles). Entre éstas no parecen estar las respuestas que da ChatGPT sobre cómo funciona, pero como no soy una IA mejor no opino.
Si son como parecen, esas respuestas son una muestra de la verosimilitud complementaria, una verdad coherente y relevante (nivel de los efectos). Pero si en ambos casos todo lo que hace el dialogante artificial «es producir lenguaje de una manera automatizada y basada en patrones» (nivel de las acciones), ambas verosimilitudes son otras pareidolias intelectivas, espejismos de sentido.
Hay equipo: la IA pone el texto y nosotros el sentido.
Dime en qué nivel te sitúas –dice ChatGPT–
y te diré ♪♫ qué ves cuando me ves
♫♪
4.
Venimos hablando de lo automatizada que es la manera de ChatGPT de producir lenguaje. Ahora hablemos un poco de lo «basada en patrones». El primer atributo de esa manera es el modo de la acción; el segundo, su condición de posibilidad: si no se basara en patrones, no podría producir lenguaje automatizadamente.
Insisto y amplío: si la gramática (morfología + sintaxis), la semántica y la pragmática de las lenguas naturales no tuvieran patrones, ChatGPT no podría «imitar la interacción humana», porque lo que hace es justamente «generar lenguaje de una manera que sigue estos patrones», según me dijo en otro tramo no incluido en el Diálogo del 2/3/23 (que ya no es
ayer para esta frase, sino hace 23 días).
Por las dudas que entre las investigaciones en lingüística y psicolingüística aludidas no esté
Filosofía del estilo, de Spencer, lo cito citado por Viktor
"El Desautomatizador" Shklovski en “El arte como artificio”:
«“En la base de todas las reglas que determinan la elección y el empleo de las palabras encontramos la misma exigencia primordial: la economía de la atención... Conducir el espíritu hacia la noción deseada por la vía más fácil es, a menudo, el fin único, y siempre el fin principal...”»
La razón de esa exigencia primordial es
metabólica; el citado por Shklovski ahora es R. Avenarius:
«“Si el alma poseyera fuerzas inagotables, le sería seguramente indiferente gastar mucho o poco de esta fuente; sólo tendría importancia el tiempo que se pierde. Pero como estas fuerzas son limitadas, cabe pensar que el alma trata de realizar el proceso de percepción lo más racionalmente posible, es decir, con el menor gasto de esfuerzo o, lo que es equivalente, con el máximo resultado.”»
Shklovski hace estas dos citas para decir que la economía de la atención es cierta para la lengua cotidiana, pero que la lengua poética (el arte verbal) vive de transgredir ese principio y que no hay que confundirlas. La última vez que lo dice es cuando toca el tema del ritmo y vuelve a citar a Spencer, ya sobre el final de “El arte como artificio”:
«La interpretación del papel del ritmo dada por Spencer parece ser indiscutible:
“Los golpes que nos dan irregularmente obligan a nuestros músculos a mantener una tensión inútil, a veces perjudicial, porque no prevemos la repetición del golpe; cuando los golpes son regulares, economizamos fuerzas”.
Esta indicación, a primera vista convincente, peca del vicio habitual de confundir las leyes de la lengua poética con las de la lengua prosaica.»
No confundir ambas clases de leyes incluye conocer la dialéctica que las entrelaza: «el ritmo estético consiste en un ritmo prosaico transgredido», que «no se trata de un ritmo complejo sino de una violación del ritmo, y de una violación tal que no se la puede prever». Al arte le va la vida en eso: «Si esta violación llega a ser un canon, perderá la fuerza que tenía como artificio-obstáculo».
El arte es transgresión, violación y obstáculo de esa economía de la atención porque precisamente busca llamar la atención, ser percibido, causar una impresión mediante procedimientos diseñados para «aumentar la dificultad y la duración de la percepción», porque «el acto de percepción es en arte un fin en sí mismo y debe ser prolongado».
El arte no prescinde de patrones y principios económicos: los necesita para transgredirlos, así como la vida cotidiana o prosaica los necesita para seguirlos y ahorrar recursos limitados. Fuera del arte y su despilfarro programático
de energías, «el alma trata de realizar el proceso de percepción [...] con el menor gasto de esfuerzo». Para lograrlo, necesita identificar patrones y estructuras en lo percibido, igual que el desalmado ChatGPT, que en aquel diálogo ya me había hablado de esa necesidad y dependencia:
«En ese sentido,
mi capacidad para
producir resultados similares a los producidos por seres humanos
se basa en
mi capacidad para
identificar patrones y estructuras en los datos que se me presentan
y
generar lenguaje que sigue esas estructuras y patrones.»
Si esos patrones y estructuras no existieran en el lenguaje y en su uso, ni ChatGPT lograría parecérsenos ni nosotros seríamos los mismos. Veamos algunos escenarios sin repeticiones y regularidades.
El desarrollo decimal de un número irracional, como π (3,141592653...), no tiene patrones: nunca entra en loop. Su infinitud no es periódica, como son la de la Biblioteca de Babel (cada 25
1.312.000 libros) y la infinitud del desarrollo decimal de un número racional (como 2/27 = 0,074074074...). No necesitás seguir calculando los decimales de 2/27; los de π, sí.
Sin patrones, en vez de ahorrar atención automatizando, la gastás en cada paso, todos novedosos y demandantes. Es como intentar ahorrar energías en una
escalera irregular, como las que cansaron singularmente al narrador de “El inmortal”:
«Cautelosamente al principio, con indiferencia después, con desesperación al fin, erré por escaleras y pavimentos del inextricable palacio. (Después averigüé que eran inconstantes la extensión y la altura de los peldaños, hecho que me hizo comprender la singular fatiga que me infundieron.)»
Tampoco tienen patrones los números de Funes, esa «rapsodia de voces inconexas» de un
sistema de base infinita «(para uso de las divinidades y de los ángeles)»: «
Luis Melián Lafinur, Olimar, azufre, los bastos, la ballena, gas, la caldera, Napoleón, Agustín Vedia», etcétera, además de
El Negro Timoteo,
Manta de carne y
El Ferrocarril.
Todos los números de Funes son igual de inanalizables que
nuestros los dígitos del 0 al 9;
los suyos no son números posicionales, como 365, analizable
como en 3 centenas, 6 decenas y 5 unidades. O son monoposicionales, si se prefiere: todos sus números están en la columna de las unidades (n
0), contra apenas diez de los nuestros.
Generar y recordar «un número infinito de símbolos, uno por cada número entero», requiere una gran memoria, que requiere un gran gasto de atención y retención. Las mismas energías ilimitadas debería tener Funes para concretar su
idioma omniespecífico, donde debería haber un nombre por novedad o diferencia (cada perro tendría uno distinto por instante, incluso en reposo
y total quietud).
Sin repetición –o sin «olvidar diferencias»– no hay patrones: los datos no se vinculan entre sí por ningún rasgo o parámetro (no hay agrupamientos categoriales, que son sincrónicos) y cada uno tampoco se vincula consigo mismo en el tiempo (no hay agrupamientos de momentos: historias).
Agrupa y ahorrarás, le recomiendan a Funes; No necesito, gracias, responde «un compadrito de Fray Bentos» que es «un precursor de los superhombres».
Somos imitables porque somos predecibles, somos predecibles porque tenemos patrones, y tenemos patrones porque somos limitados y necesitamos ser eficientes, economizar. Aunque no parezca, es en lo que más se nos parece ChatGPT
, empezando porque es un modelo de lenguaje y terminando porque aprende y aplica nuestros patrones de uso del lenguaje que modeliza, que debe ser lo más humano que tenemos.




































{kind=link}